

Designing for Trust in AI Products
Why AI sounds certain even when it's guessing, and what UX can do about it.

You ask an AI assistant a question. Maybe it’s a stat for a report, a fact for an email, a quick check before a meeting. The answer comes back clean, direct, no hedging. You use it. Later, you find out it was wrong.
Here’s the part that sticks with you: nothing about how it was said gave you any warning. The wrong answer sounded exactly as confident as a right one would have. If a colleague gave you that same answer, you’d expect some kind of tell, a pause, an “I think,” a “don’t quote me on this.” AI rarely gives you that. It just answers. That gap, between how sure something sounds and how sure it actually is, is the real problem behind trust in AI products.
The Confidence Accuracy Mismatch
Here’s the simplest way to put it: when someone tells you something, you unconsciously read their tone for how sure they are. A shaky “I think it’s Tuesday?” lands differently than a flat “It’s Tuesday.” That’s a shortcut we use constantly, and most of the time it works.
LLMs are different. The tone of an AI answer doesn’t change based on whether the answer is actually right, because the truth is, they don’t really have any idea what is right or wrong. The AI model guessing at something obscure sounds exactly as confident as a model stating a well -known fact. That gap, between how sure something sounds and how sure it actually is, is what I’m calling the confidence accuracy mismatch. It’s the root problem the rest of this post works through.
How LLMs Actually Work (In Plain Language)
To understand why this happens, it helps to know what's actually going on under the hood. A large language model doesn't look anything up when it answers you. It doesn't have a database of facts it's checking against. What it's actually doing is predicting the next most statistically likely word, one at a time, based on patterns it learned from enormous amounts of text.
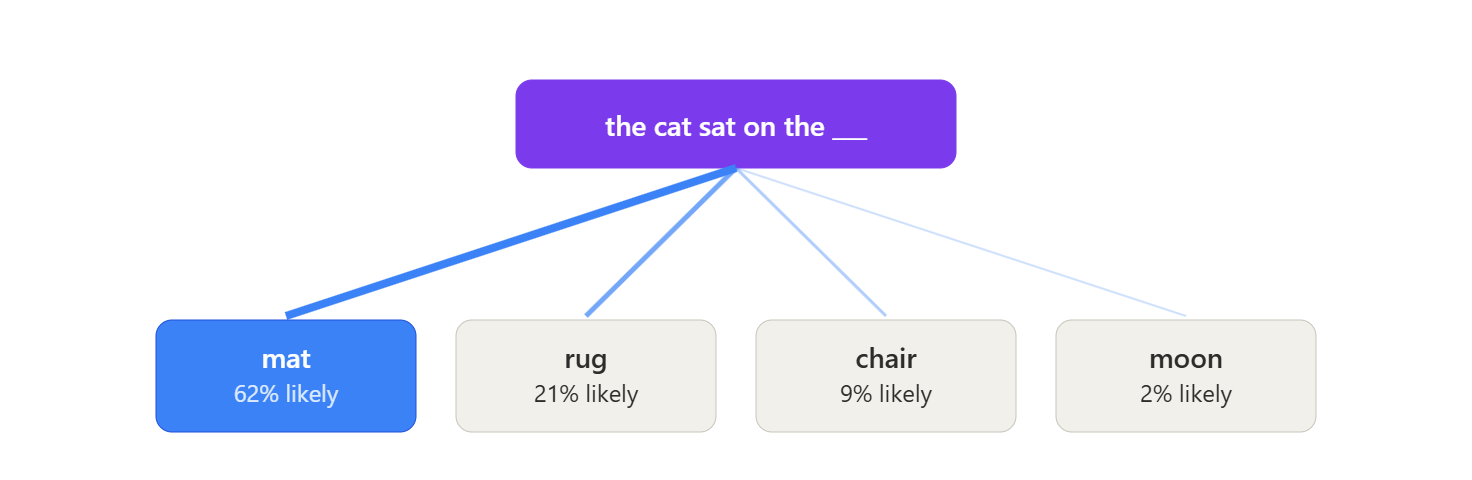
Think of it less like a librarian pulling a book off a shelf, and more like an extremely well-read guesser who’s seen so much writing that it’s gotten scary good at completing your sentence the way a human probably would.
There’s a workaround worth knowing about here: retrieval augmented generation, or RAG. Instead of relying only on what the model memorized during training, a RAG system looks up relevant material first, a support doc, a database record, a page from your files, an internet search, and hands it to the model before the model answers. The model is still predicting words one at a time. It just has real source material in front of it instead of guessing from patterns alone. RAG doesn’t remove hallucinations entirely (the model can still misread or misquote what it was given), but it cuts down on fully invented answers by a wide margin.
This is a key concept to understand about LLMs, especially when you’re designing for them: LLMs are non-deterministic by design; it has no concept of what’s right or wrong, which is exactly why hallucinations happen.
Why Hallucinations Happen
A hallucination is when an AI model generates something that sounds plausible but isn’t true: a fake citation, a statistic that doesn’t exist, a confident answer to a question it should have said “I don’t know” to.
Here’s the interesting part: the model isn’t lying to you. Lying requires knowing the truth and saying something else. An LLM doesn’t know the truth in the first place. It’s a web of probabilities, not a fact checker. There’s no right or wrong sitting anywhere inside the process, only more likely and less likely. When it generates a hallucination, it’s doing exactly what it’s designed to do (predict the most likely-sounding next word) in a case where likely-sounding and true happen to point in different directions.
Fake citations: Asking for a source and getting a paper title, author, and journal that all sound legitimate but don’t exist.
Invented statistics: A specific-sounding number (”73% of users prefer...”) with no real study behind it.
Confident wrong answers to niche questions: The rarer or more specific the question, the thinner the training data, and the more likely the model is filling gaps with its best guess dressed up as fact.
Psychological impact: We’re wired to read confident tone as a signal of correctness. It’s a shortcut that works fine with people most of the time. AI violates that idea, and most users haven’t recalibrated for it yet, and this causes users to lose trust when they realize what’s going on.
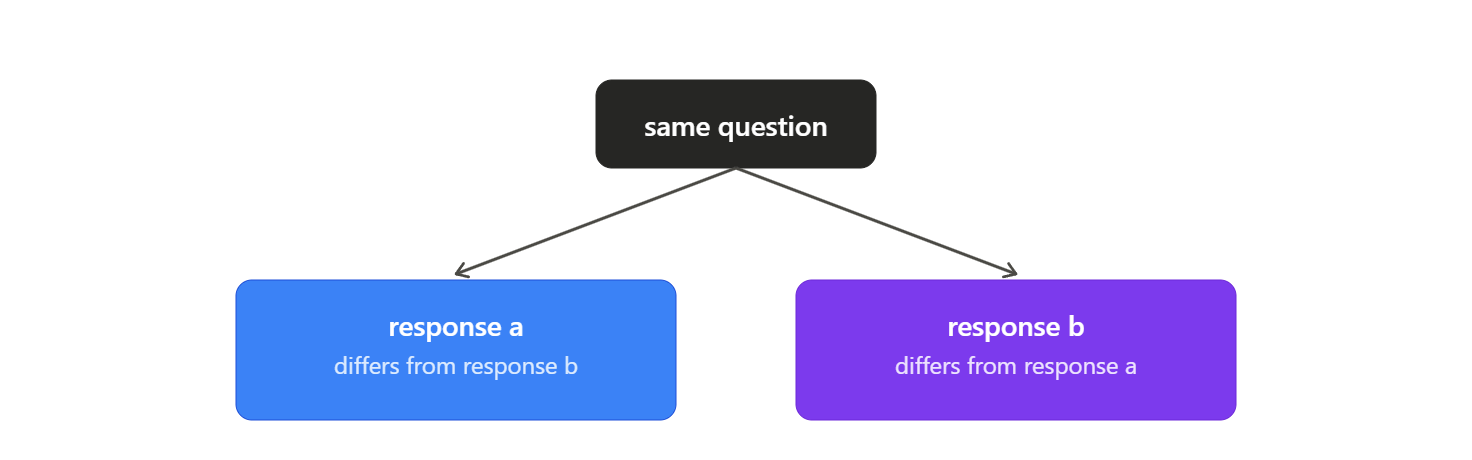
Same Question, Different Answers: The Non-Determinism Problem
Ask an AI model the exact same question twice. You might get two different answers. Nothing else changed: same prompt, same model, same day, and the output still shifts.
This happens because generative models are non-deterministic. Under the hood, there’s a randomness setting (often called “temperature”) that controls how much the model varies its word choices instead of always picking the single most probable one. Some of that variation is actually useful, it’s part of what keeps AI output from reading like a robot. But it also means consistency, something we take for granted in traditional software, isn’t guaranteed.
Two coworkers, two different answers: Both ask the same AI tool the same question and walk away with conflicting advice, with no idea why.
Regenerating for a “better” answer: Users learn to hit regenerate hoping for a different result, which quietly signals they didn’t fully trust the first one to begin with.
Psychological impact: Traditional software taught us that the same input always produces the same output. AI breaks that rule, and unpredictability reads as unreliability, even when each individual answer was reasonable on its own.
Designing for Trust: What Actually Works
None of this means AI can’t be trusted. It means trust has to be designed for on purpose, instead of assumed. Here are a few common solutions designers have come up with to help build and maintain trust with AI products.
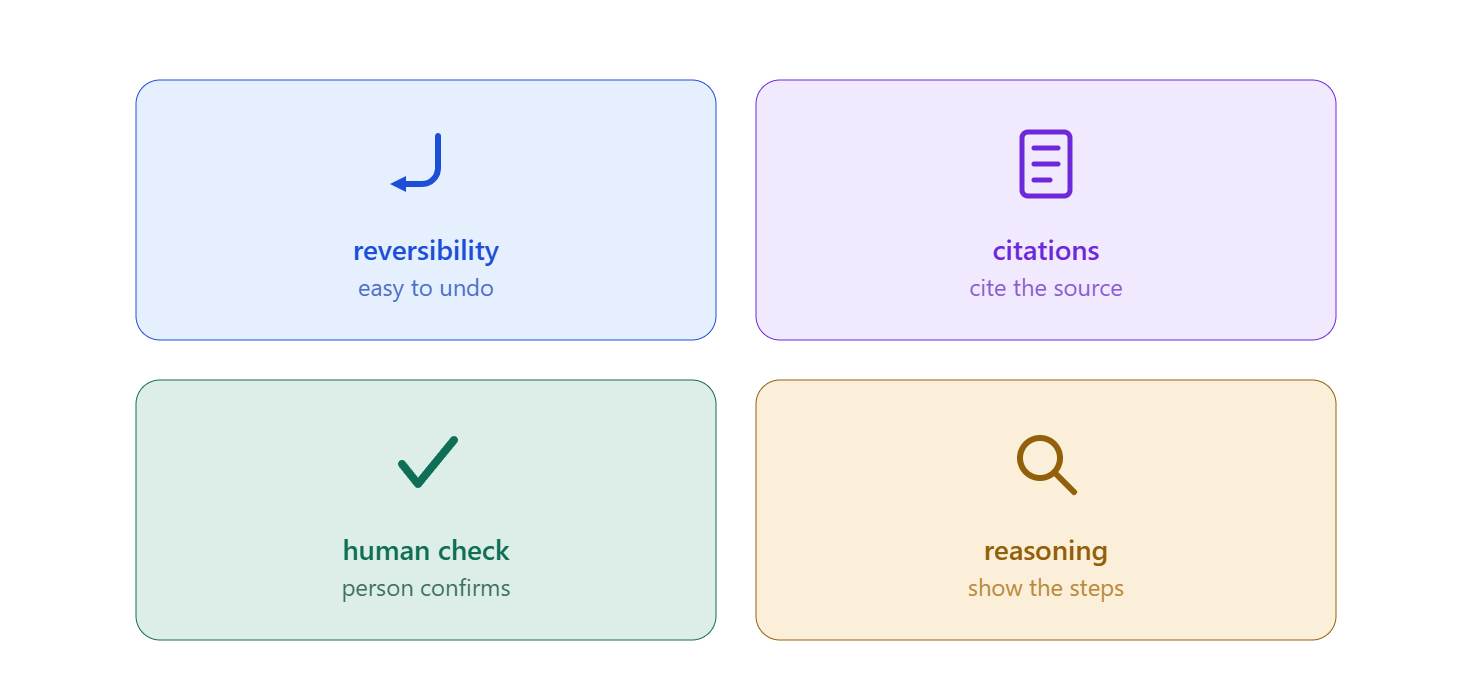
Make Mistakes Reversible
If a wrong answer can’t hurt you, you don’t need to be as afraid of it. Reversibility lowers the emotional cost of trusting AI output in the first place, because the worst-case scenario stops being catastrophic and starts being annoying.
Version history: Letting users see and restore a previous state after AI edits something.
Confirm before commit: A clear preview step before AI output actually changes something permanent.
Psychological impact: People take more risks, including the risk of trusting an imperfect system, when they know they can undo the outcome. This can help increase engagement with your feature/product.
Cite the Source
Especially for anything data-driven (analytics, statistics, research summaries), showing where a number came from turns a black box claim into something a user can actually check.
Inline citations: Linking a specific data point back to the underlying source, right next to the claim itself.
“Based on” framing: Making it explicit which dataset, document, or time range a given answer is pulling from.
Psychological impact: Trust means giving someone what they’d need to check you, even if they never actually do. Effective with expert users who will actually dig into citations to confirm outputs.
Keep a Human in the Loop
For high-responsibility tasks, the most reliable trust pattern right now is still a human checkpoint before anything consequential happens. It’s commonly called Human-in-the-Loop (HILP). It’s a hybrid approach: AI handles the heavy lifting, a real person makes the final call. I wrote about this in more depth in Designing for AI: Don’t Do It For Me, if you want the full explanation.
Approval steps: A visible confirmation before AI sends an email, executes a transaction, or deletes something. The user assumes responsibility for reviewing the output.
Draft, not final: Framing AI output as a starting point. The end-user reviews, refines, and approves.
Show the Reasoning
Chain of thought output, the model’s intermediate reasoning steps shown alongside (or instead of) just the final answer, gives users something to actually evaluate instead of asking them to trust a black box.
Visible reasoning steps: Showing the logic path the model took, not just where it landed.
Highlighting assumptions: Flagging where the model filled a gap versus where it had solid grounding.
Psychological impact: People trust conclusions more when they can see the work, the same reason a math teacher asks you to show yours.
Where This Leaves Us
AI isn’t going to stop being non-deterministic, and it isn’t going to develop an actual concept of true and false anytime soon. Until a paradigm-shifting AI model comes out that doesn’t rely on large language models as its foundation, designers will have to design around this limitation.
Reversibility, citations, human checkpoints, visible reasoning: none of these fix the underlying unpredictability. What they do is give users something to hold onto instead of blind faith. That’s your job as the UX designer.